가상 면접 사례로 배우는 대규모 시스템 설계 기초 2 - 광고 클릭 이벤트 집계를 정리한 내용입니다.
1. Introduction
온라인 광고의 핵심적 혜택은 실시간 데이터를 통해 광고 효과를 정량적으로 측정할 수 있다는 점이다. 디지털 광고의 핵심 프로세스는 RTB(Real-Time Bidding), 즉 실시간 경매라 부른다. 이 경매 절차를 통해 광고가 나갈 지면(inventory) 를 거래한다.
RTB 프로세스에서 속도와 데이터 정확성이 중요하다. 광고 클릭 이벤트 집계는 온라인 광고가 얼마나 효율적인지 측정하는 데 결정적인 역할을 하며, 클릭 집계 결과에 따라 예산 조정, 타깃&키워드 변경해 광고 전략을 수정할 수 있다. 핵심 지표로는 CTR(Click-Through Rate, 클릭률), CVR(Conversion Rate, 전환율) 등이 있으며, 집계된 광고 클릭 데이터에 기반하여 개선된다.
2. 문제 이해 및 설계 범위 확정
- 입력 데이터 형태
- 여러 서버에 분산된 로그 파일이며, 수집 시 로그 파일의 끝에 추가된다.
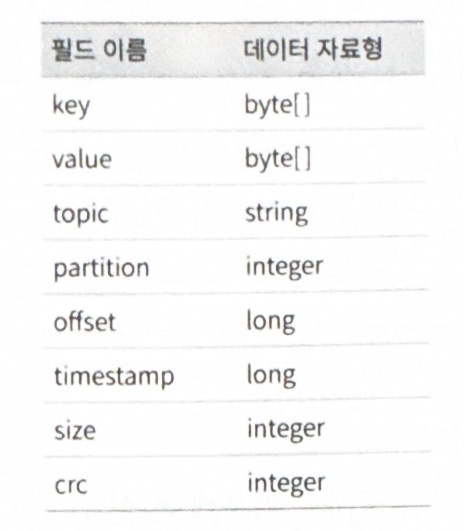
- 클릭 이벤트 필드 : ad_id, click_time-stamp, user-id, ip, country
- 데이터 양
- 광고 클릭 : 매일 10억개
- 광고 : 2백만 회 게재
- 광고 클릭 이벤트 수 : 매년 30% 증가
- 지원 질의(query)
- M분 간 클릭 이벤트 수
- 질의 기간과 광고 수 (집계는 매분)
- ip, user_id, country 등의 속성을 기준으로 상위 2개 질의 결과 필터링
- 엣지 케이스(edge case)
- 예상보다 늦게 도착하는 이벤트
- 중복 이벤트
- 시스템 복구 고려
- 지연 시간 요건
- 모든 처리가 수분 이내 완료
- RTB 지연 시간 : 일반적 1초 미만
- 광고 클릭 이벤트 집계 : 수 분 지연 허용
3. 데이터 모델 (원시 데이터 vs 집계 데이터)
- 원시 데이터 보관
- 장점
- 원본 데이터 손실 없이 보관
- 데이터 필터링 및 재계산 지원
- 단점
- 막대한 데이터 용량
- 낮은 질의 성능
- 장점
- 집계 결과 데이터 보관
- 장점
- 데이터 용량 절감
- 빠른 질의 성능
- 단점
- 원시 데이터 손실
- 장점
어떤 데이터를 저장하는 것이 적합할까? 뻔할 수 있지만 원시, 집계 데이터 데이터 모두 저장하는 것을 추천한다. 데이터의 사용 용도에 따라 적합한 데이터가 다르기 때문이다. 원시 데이터는 디버깅, 백업 데이터로 활용하는데 적합한 반면 집계 데이터는 효율적인 질의를 위한 튜닝 목적으로 사용된다. 광고 클릭 이벤트 데이터 특성상 시계열 데이터이며 쓰기, 읽기 연산이 상당히 높은 특성을 고려해야 한다.
데이터 베이스 선택의 기준은 아래와 같다.
- 데이터 형태(e.g. 관계형, 문서, 이진 대형 객체)
- 작업 흐름 (e.g. 읽기, 쓰기 중심)
- 트랜잭션 지원 여부
- 질의 과정에서 온라인 분석 처리(OLAP) 함수 사용 빈도 여부 (e.g. SUM, COUNT)
4. 계략적 설계안
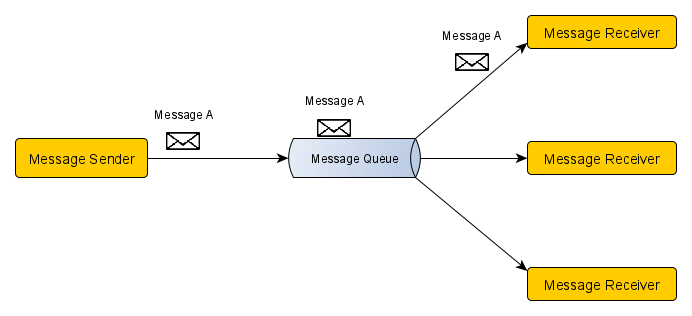
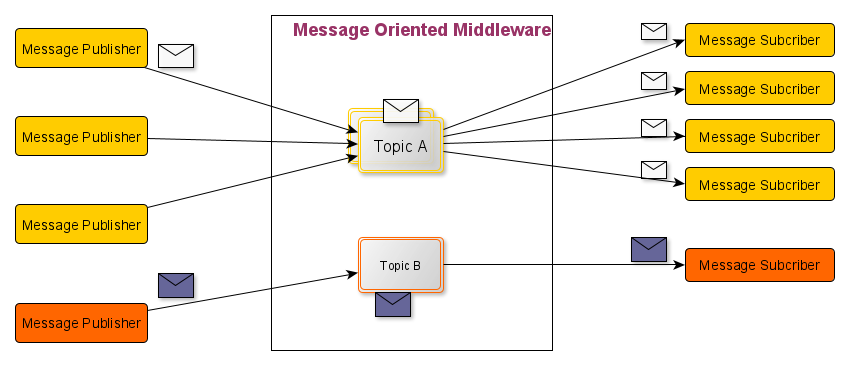
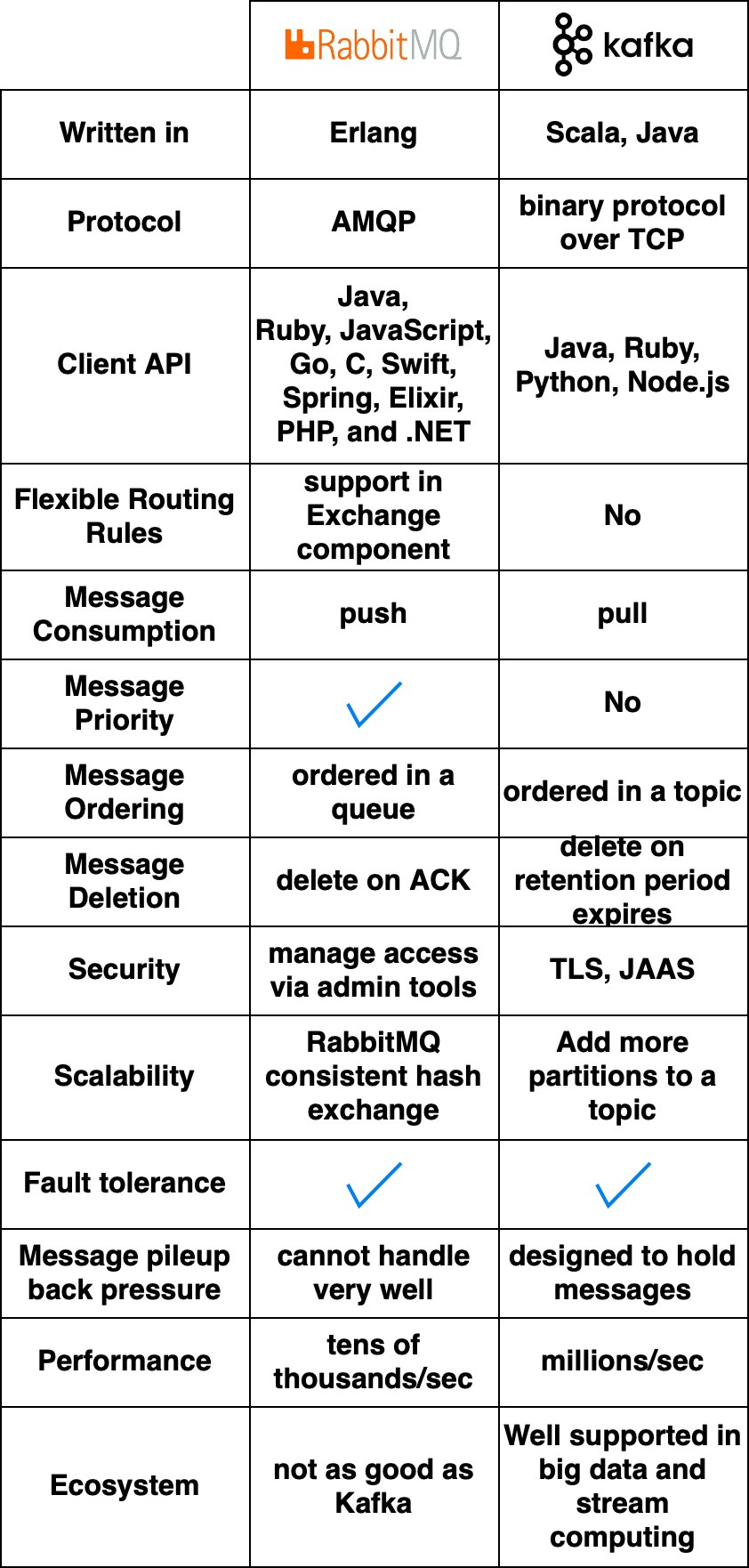
광고 클릭 데이터는 동기 처리에 한계가 있다. 비즈니스 특성상 트래픽에 유연하게 대응해야 하기 때문이다. 또한 소비자 처리 용량을 넘어서는 경우와 같은 예기치 않은 문제가 발생할 수 있으므로 비동기 처리가 핵심이다. 비동기 처리를 위한 방법으로는 카프카와 같은 풀 방식의 메시지 큐를 통해 생산자와 소비자의 결합을 끊는 것이다. 푸쉬 방식은 생산자의 메시지 전송 속도에 따라 소비자의 스펙이 갖춰줘야 하지만 풀 모델은 메시지 구독 속도를 조절할 수 있기 때문이다.
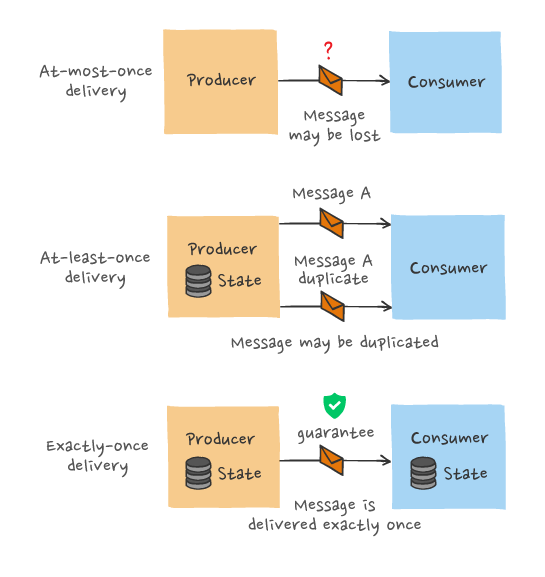
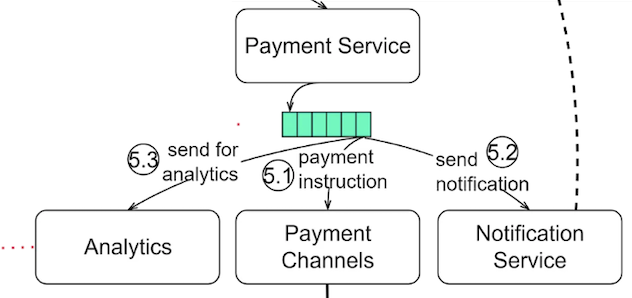
또한 집계 결과를 DB 에 바로 기록하지 않는데 이는 정확하게 한 번 데이터 처리를 위해 원자적 연산(atomic commit) 을 보장하기 위함이다.
(1) 집계 서비스
- 맵 노드 : 데이터 출처에서 읽은 데이터를 필터링하고 변환하는 역할을 한다.
- 집계 노드 : 광고별 클릭 이벤트 수를 매 분 메모리에 집계한다.
- 리듀스 노드 : 모든 집계 노드가 산출한 결과를 최종 결과로 축약한다.
5. 상세 설계
(1) 스트리밍 vs 일괄처리
스트리밍 처리는 데이터를 오는 대로 처리하고 거의 실시간으로 집계된 결과를 생성하는 데 사용하고, 일괄 처리는 처리 경로를 백업하기 위해 활용한다.
일괄 처리 및 스트리밍 처리 경로를 동시에 지원하는 시스템의 아키텍처를 람다(lambda) 이다. 람다 아키텍처의 단점은 유지 관리해야 코드가 분리된다는 점이다. 반면, 카파 아키텍처(kappa) 는 일괄 처리와 스트리밍 처리 경로를 하나로 결합하여 이 문제를 해결해야 한다.
(2) 시간
이벤트 타임 스탬프는 이벤트 시각과 처리 시간으로 구분해서 관리할 수 있다. 이벤트 발생 시각에 타임 스탬프를 처리한다면 광고 클릭 시점을 정확히 파악할 수 있어 집계 결과가 정확하다. 하지만 생성 주체가 클라이언트에서 고의로 조작할 수 있는 문제가 있다. 처리 시각은 서버에서 타임 스탬프를 관리하기 때문에 보다 신뢰할 수 있지만 네트워크 지연, 비동기 처리로 인한 지연에 의한 집계 결과가 부정확 해질 수 있는 단점이 있다.
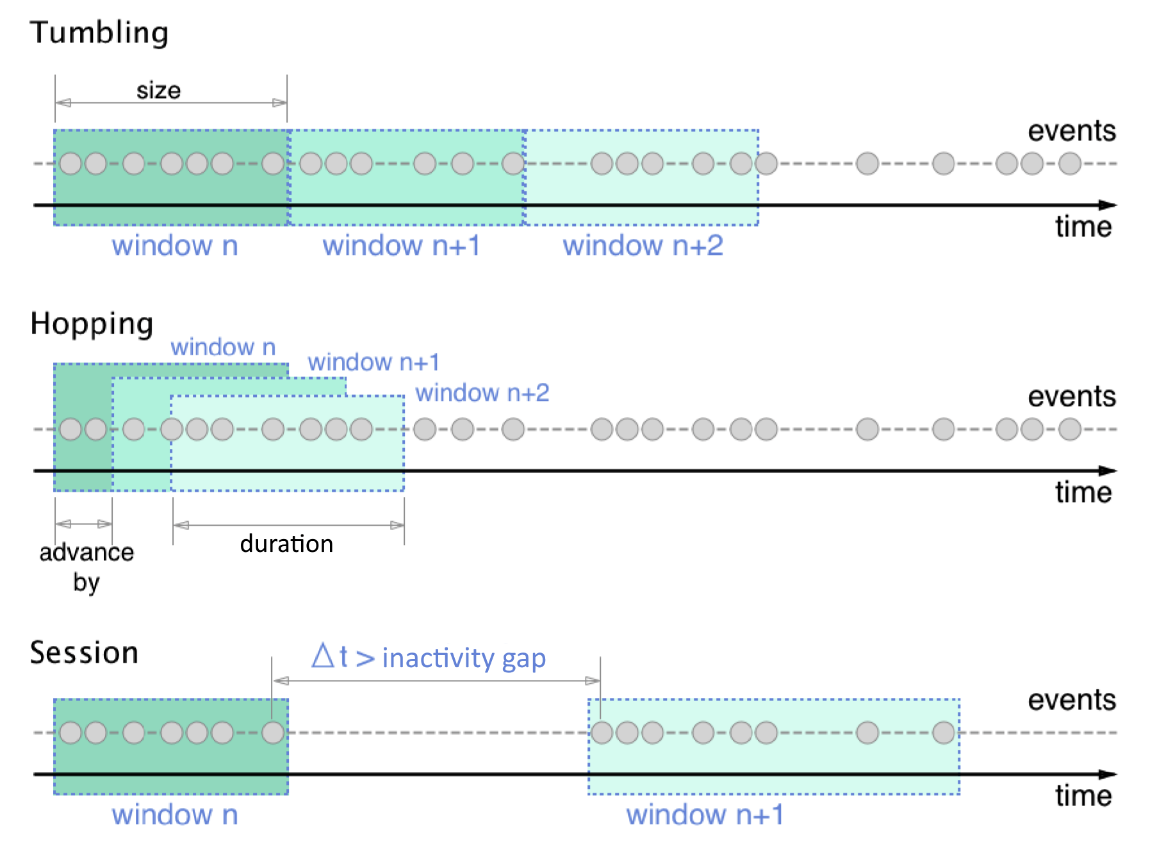
집계 처리를 1분 단위로 끊어지는 방식을 텀블링 윈도우(tumbling window) 라 한다. 텀블링 윈도우는 이벤트 발생 시각과 처리 시각의 차이가 큰 경우 이벤트가 집계되지 못할 수 있는 위험이 있다. 이와 같은 문제는 워터마크를 이용해 해결할 수 있다. 워터마크(water mark)는 윈도우에 속하는 모든 데이터가 도착할 것으로 예상하는 시점을 나타내는 기준점을 두어 지연 데이터를 윈도우에 포함시키는 방식을 말한다. 윈도우에는 텀블링 윈도우, 고정 윈도우, 호핑 윈도우, 슬라이딩 윈도우, 세션 윈도우 등이 있다.
Reference
'architecture > system' 카테고리의 다른 글
| [가상 면접 사례로 배우는 대규모 시스템 설계 기초 2] 지표 모니터링 및 경보 시스템 (0) | 2024.05.04 |
|---|---|
| [가상 면접 사례로 배우는 대규모 시스템 설계 기초 2] 분산 메시지 큐 설계 (0) | 2024.04.29 |