
가상 면접 사례로 배우는 대규모 시스템 설계 기초 2 - 지표 모니터링 및 경보 시스템을 정리한 내용입니다.
1. 시스템 설계 시의 질문 & 고려 사항
- 지표 데이터 보관 기간
- 장기 보관 저장소 이동 시 지표의 해상도(resolution) 을 낮춰도 괜찮은지?
- 경보 채널에 관한 지원? (.e.g. 이메일, 전화, 웹훅)
- 분산 시스템 추적 기능(distribution system tracing function) 제공 여부
2. 개략적 설계안 제시
지표 모니터링 시스템을 구축하기 위해서는 데이터 수집, 데이터 전송, 데이터 저장소, 경보, 시각화를 담당하는 컴포넌트가 필요하다. 데이터 수집은 여러 출처로 부터 데이터를 수집하고, 지표 데이터를 지표 모니터링 시스템으로 전송해 데이터 저장소에 저장한다. 전송된 데이터를 분석하여 이상 징후를 감시하여 경보를 발생한다. 발생한 경보는 다양한 채널을 통해 발송한다.
(1) 데이터 모델
지표 데이터는 통상 시계열(time series) 데이터 형태로 기록한다. 시계열 데이터는 시간의 순서에 따라 관측된 데이터를 말한다. 시계열 데이터에는 타임스탬프(timestamp), 레이블(label) 이 포함된다. 최근 시장에는 많은 모니터링 소프트웨어 공통 형식을 준수한다. (e.g. 프로메테우스, OpenTSDB)
(2) 데이터 접근 패턴
쓰기 연산은 꾸준하게 많은 연산 부하를 감당해야 하고, 읽기 연산은 일시적으로 증가했다가 잠잠해진다.
(3) 데이터 저장소 시스템
데이터 저장소 시스템은 설계안의 핵심이다. 이전에 언급한 데이터 모델과 접근 패턴을 다시 살펴보면 시계열 데이터이고 높은 쓰기 연산, 일시적으로 높은 읽기 연산이다.
RDB 높은 쓰기와 읽기 연산에 좋은 성능을 보이지 못하며 시계열 데이터를 시계열 데이터 연산에 최적화되어 있지 않다. (e.g. 여러 태그, 레이블에 관한 지원 지수 이동에 따른 평균을 지속적으로 갱신 및 쓰기 연산)
NoSQL 에서 시계열 데이터에 최적화된 데이터 베이스가 많이 존재한다. 뿐만 아니라 데이터 보관 기간, 데이터 집계 기능을 제공한다. 대표적인 DB 로는 InfluxDB, 프로메테우스가 있다.
3. 개략적 설계안
- 지표 출처 : 지표 데이터가 만들어지는 역할
- 지표 수집기 : 지표 데이터를 수집하고 시계열 데이터에 기록하는 역할
- 시계열 데이터베이스 : 지표 데이터를 시계열 데이터 형태로 보관하는 저장소
- 질의 서비스 : 시계열 데이터베이스에 보관된 데이터를 질의하고 가져오는 과정을 돕는 서비스
- 경보 시스템 : 경보 알림을 전송하는 역할
- 시각화 시스템 : 지표를 다양한 그래프/차트로 시각화 하는 기능을 제공하는 시스템
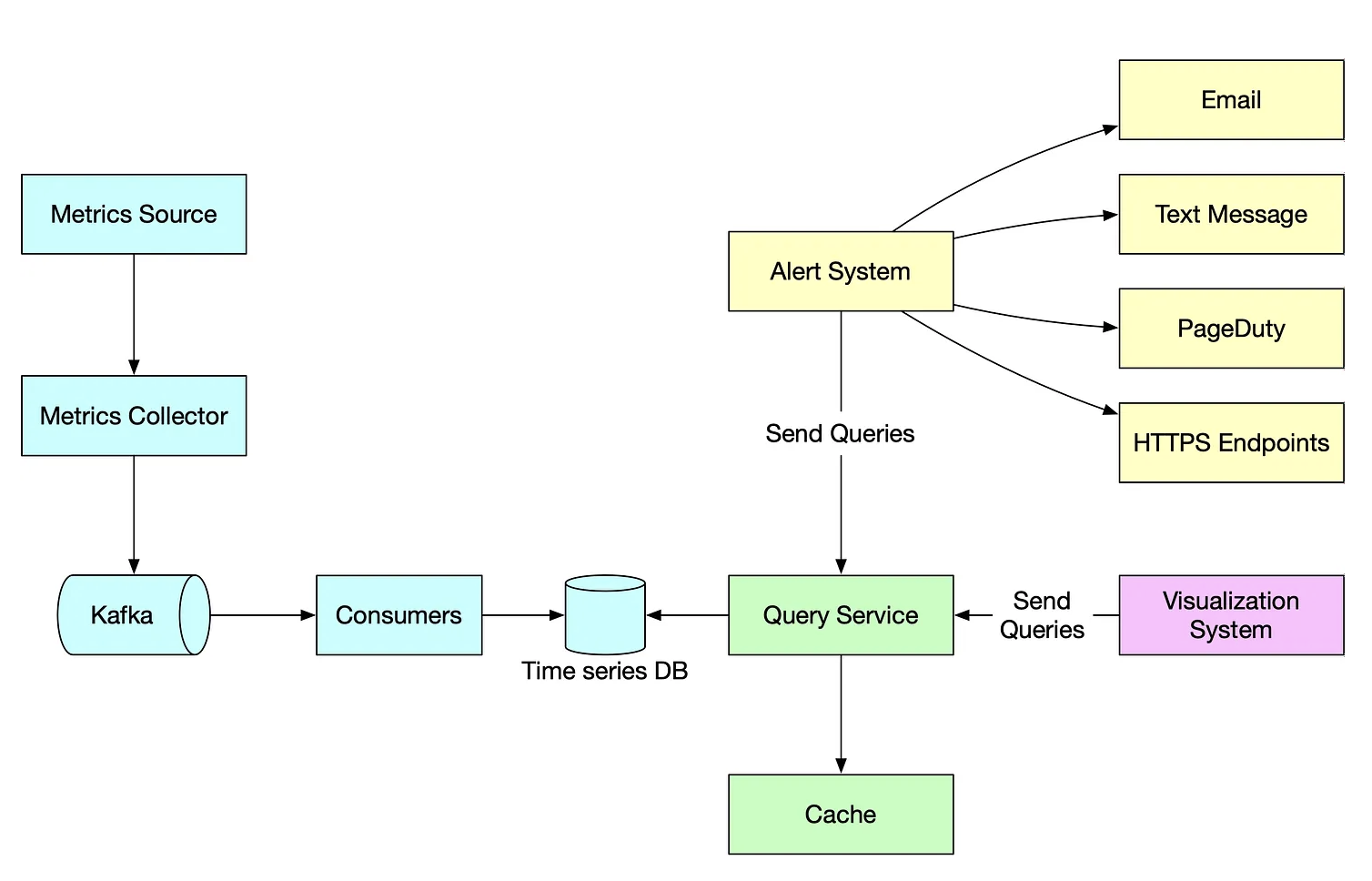
4. 구체적 설계안
(1) 지표 수집
지표가 수집되는 흐름은 풀 모델, 푸시 모델이 있다. 풀 모델은 지표 수집기가 지표 출처로 부터 지표 데이터를 가져오는 방식이다. 대표적인 사례로는 프로메테우스가 있다.
풀 모델은 지표 출처에 관한 메타 데이터를 관리하기 위해 서비스 탐색 서비스(Service Discovery Service, SDS) 이다. 각 서비스는 SDS 에게 가용성 정보를 전달하고, SDS 는 서비스 엔드포인트의 목록 변화가 발생하면 지표 수집기에 통보한다.
풀 모델에서 지표 수집기에서 발생할 수 있는 문제는 데이터 중복해서 가져올 수 있다는 점이다. 이를 방지하기 위해 중재 매커니즘이 필요하며 이에 관한 방안이 안정 해시 링(consistent hash ring) 이다. 안정 해시 링은 해시 링 구간마다 해당 구간에 속한 서버로 부터 생산하는 지표의 수집을 담당하는 수집기 서버를 지정하는 것이다.
푸시 모델은 서비스(지표 출처)에 수집 에이전트를 통해 지표 수집기에 지표 데이터를 주기적으로 전달하는 방식이다. 대표적인 사례로는 아마존 클라우드와치(cloudwatch), 그래파이트(graphite) 가 있다.
푸시 모델에서 고려해야 할 사항은 자동 규모 확장(auto-scaling)환경이다. 서버의 동적 추가, 삭제과정에서 지표 데이터가 소실될 수 있기 때문에 이를 방지하기 위해 지표 수집기에 대해서도 자동 규모 확장(auto-scaling) 을 고려해 볼 필요가 있다.
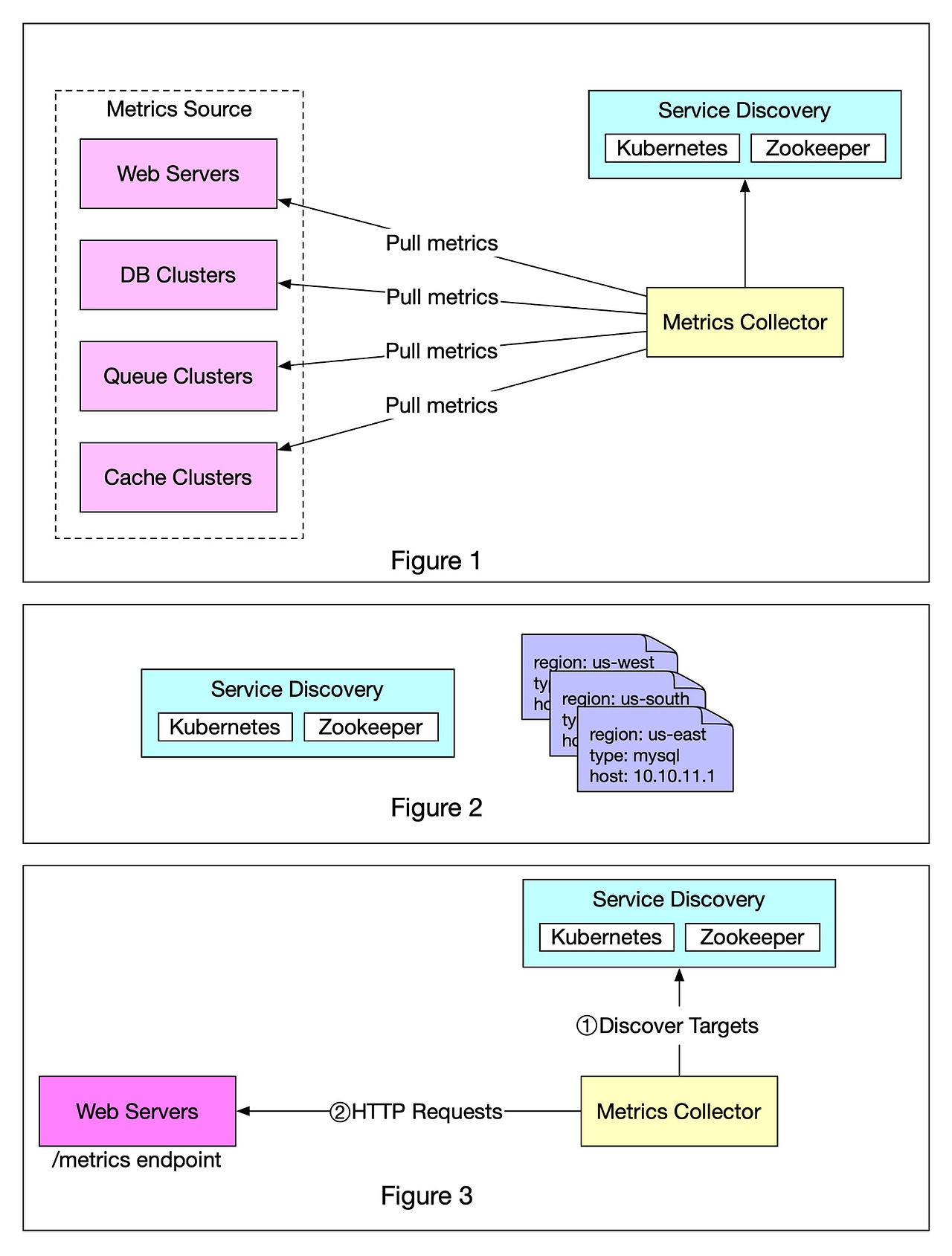
(2) 데이터 집계 시점
- 수집 에이전트가 집계
- 특정 카운터 값을 분 단위로 집계하여 지표 수집기에 전달할 수 있다.
- 클라이언트에 수집 에이전트는 복합한 집계 로직은 지원하지 않는다.
- 데이터 수집 파이프라인에서 집계
- 데이터 저장소 기록 이전에 집계하기 위해서는 플링크(Filnk) 같은 스트림 프로세싱 엔진이 필요하다.
- 데이버 베이스에는 계산 결과만 기록하므로 저장 내용이 많이 줄어든다.
- 계산 결과만 기록하므로 정밀도, 유연성 측면이 아쉬울 수 있다.
- 질의 시에 집계
- 로우 데이터를 보관한 다음 질의시에 필요한 시간 구간에 맞게 집계한다.
- 데이터 손실 문제는 없으나 전체 데이터 세트를 대상으로 집계 결과를 계산해야 하므로 속도가 느릴 수 있다.
(3) 질의 서비스
질의 서비스는 시계열 데이터 베이스에 존재하는 데이터를 통해 시각화, 경보 시스템의 접수된 요청을 처리하는 역할을 담당한다. 질의 처리 전담 서비스를 구축하면 클라이언트(e.g. 시각화, 경보 시스템) 와 시계열 데이터베이스를 자유롭게 다른 제품으로 교체할 수 있다.
(4) 저장소 계층
- 저장 용량 최적화
- 데이터 인코딩 및 압축 : 데이터를 인코딩, 압축하면 크기를 상당히 줄일 수 있다.
- (1610087371, 1610087381 → 1610087371, 10)
- 다운 샘플링 : 데이터의 해상도를 낮춰 저장소 요구량을 줄이는 방법이다. 보관 기간이 오래된 데이터에 대해 해상도를 줄이는 방식으로 선택한다.
- 냉동 저장소 : 잘 사용되지 않는 비활성 상태의 데이터를 저장하는 곳이다.
Reference
'architecture' 카테고리의 다른 글
| [데이터 중심 애플리케이션 설계] 분산 시스템의 골칫거리 (1) | 2024.06.08 |
|---|---|
| [가상 면접 사례로 배우는 대규모 시스템 설계 기초 2] 호텔 예약 시스템 (0) | 2024.05.21 |
| [가상 면접 사례로 배우는 대규모 시스템 설계 기초 2] 광고 클릭 이벤트 집계 (1) | 2024.05.11 |
| [가상 면접 사례로 배우는 대규모 시스템 설계 기초 2] 분산 메시지 큐 설계 (0) | 2024.04.29 |
| 모놀로식, MSA 장단점 (1) | 2024.03.04 |
가상 면접 사례로 배우는 대규모 시스템 설계 기초 2 - 지표 모니터링 및 경보 시스템을 정리한 내용입니다.
1. 시스템 설계 시의 질문 & 고려 사항
- 지표 데이터 보관 기간
- 장기 보관 저장소 이동 시 지표의 해상도(resolution) 을 낮춰도 괜찮은지?
- 경보 채널에 관한 지원? (.e.g. 이메일, 전화, 웹훅)
- 분산 시스템 추적 기능(distribution system tracing function) 제공 여부
2. 개략적 설계안 제시
지표 모니터링 시스템을 구축하기 위해서는 데이터 수집, 데이터 전송, 데이터 저장소, 경보, 시각화를 담당하는 컴포넌트가 필요하다. 데이터 수집은 여러 출처로 부터 데이터를 수집하고, 지표 데이터를 지표 모니터링 시스템으로 전송해 데이터 저장소에 저장한다. 전송된 데이터를 분석하여 이상 징후를 감시하여 경보를 발생한다. 발생한 경보는 다양한 채널을 통해 발송한다.
(1) 데이터 모델
지표 데이터는 통상 시계열(time series) 데이터 형태로 기록한다. 시계열 데이터는 시간의 순서에 따라 관측된 데이터를 말한다. 시계열 데이터에는 타임스탬프(timestamp), 레이블(label) 이 포함된다. 최근 시장에는 많은 모니터링 소프트웨어 공통 형식을 준수한다. (e.g. 프로메테우스, OpenTSDB)
(2) 데이터 접근 패턴
쓰기 연산은 꾸준하게 많은 연산 부하를 감당해야 하고, 읽기 연산은 일시적으로 증가했다가 잠잠해진다.
(3) 데이터 저장소 시스템
데이터 저장소 시스템은 설계안의 핵심이다. 이전에 언급한 데이터 모델과 접근 패턴을 다시 살펴보면 시계열 데이터이고 높은 쓰기 연산, 일시적으로 높은 읽기 연산이다.
RDB 높은 쓰기와 읽기 연산에 좋은 성능을 보이지 못하며 시계열 데이터를 시계열 데이터 연산에 최적화되어 있지 않다. (e.g. 여러 태그, 레이블에 관한 지원 지수 이동에 따른 평균을 지속적으로 갱신 및 쓰기 연산)
NoSQL 에서 시계열 데이터에 최적화된 데이터 베이스가 많이 존재한다. 뿐만 아니라 데이터 보관 기간, 데이터 집계 기능을 제공한다. 대표적인 DB 로는 InfluxDB, 프로메테우스가 있다.
3. 개략적 설계안
- 지표 출처 : 지표 데이터가 만들어지는 역할
- 지표 수집기 : 지표 데이터를 수집하고 시계열 데이터에 기록하는 역할
- 시계열 데이터베이스 : 지표 데이터를 시계열 데이터 형태로 보관하는 저장소
- 질의 서비스 : 시계열 데이터베이스에 보관된 데이터를 질의하고 가져오는 과정을 돕는 서비스
- 경보 시스템 : 경보 알림을 전송하는 역할
- 시각화 시스템 : 지표를 다양한 그래프/차트로 시각화 하는 기능을 제공하는 시스템
4. 구체적 설계안
(1) 지표 수집
지표가 수집되는 흐름은 풀 모델, 푸시 모델이 있다. 풀 모델은 지표 수집기가 지표 출처로 부터 지표 데이터를 가져오는 방식이다. 대표적인 사례로는 프로메테우스가 있다.
풀 모델은 지표 출처에 관한 메타 데이터를 관리하기 위해 서비스 탐색 서비스(Service Discovery Service, SDS) 이다. 각 서비스는 SDS 에게 가용성 정보를 전달하고, SDS 는 서비스 엔드포인트의 목록 변화가 발생하면 지표 수집기에 통보한다.
풀 모델에서 지표 수집기에서 발생할 수 있는 문제는 데이터 중복해서 가져올 수 있다는 점이다. 이를 방지하기 위해 중재 매커니즘이 필요하며 이에 관한 방안이 안정 해시 링(consistent hash ring) 이다. 안정 해시 링은 해시 링 구간마다 해당 구간에 속한 서버로 부터 생산하는 지표의 수집을 담당하는 수집기 서버를 지정하는 것이다.
푸시 모델은 서비스(지표 출처)에 수집 에이전트를 통해 지표 수집기에 지표 데이터를 주기적으로 전달하는 방식이다. 대표적인 사례로는 아마존 클라우드와치(cloudwatch), 그래파이트(graphite) 가 있다.
푸시 모델에서 고려해야 할 사항은 자동 규모 확장(auto-scaling)환경이다. 서버의 동적 추가, 삭제과정에서 지표 데이터가 소실될 수 있기 때문에 이를 방지하기 위해 지표 수집기에 대해서도 자동 규모 확장(auto-scaling) 을 고려해 볼 필요가 있다.
(2) 데이터 집계 시점
- 수집 에이전트가 집계
- 특정 카운터 값을 분 단위로 집계하여 지표 수집기에 전달할 수 있다.
- 클라이언트에 수집 에이전트는 복합한 집계 로직은 지원하지 않는다.
- 데이터 수집 파이프라인에서 집계
- 데이터 저장소 기록 이전에 집계하기 위해서는 플링크(Filnk) 같은 스트림 프로세싱 엔진이 필요하다.
- 데이버 베이스에는 계산 결과만 기록하므로 저장 내용이 많이 줄어든다.
- 계산 결과만 기록하므로 정밀도, 유연성 측면이 아쉬울 수 있다.
- 질의 시에 집계
- 로우 데이터를 보관한 다음 질의시에 필요한 시간 구간에 맞게 집계한다.
- 데이터 손실 문제는 없으나 전체 데이터 세트를 대상으로 집계 결과를 계산해야 하므로 속도가 느릴 수 있다.
(3) 질의 서비스
질의 서비스는 시계열 데이터 베이스에 존재하는 데이터를 통해 시각화, 경보 시스템의 접수된 요청을 처리하는 역할을 담당한다. 질의 처리 전담 서비스를 구축하면 클라이언트(e.g. 시각화, 경보 시스템) 와 시계열 데이터베이스를 자유롭게 다른 제품으로 교체할 수 있다.
(4) 저장소 계층
- 저장 용량 최적화
- 데이터 인코딩 및 압축 : 데이터를 인코딩, 압축하면 크기를 상당히 줄일 수 있다.
- (1610087371, 1610087381 → 1610087371, 10)
- 다운 샘플링 : 데이터의 해상도를 낮춰 저장소 요구량을 줄이는 방법이다. 보관 기간이 오래된 데이터에 대해 해상도를 줄이는 방식으로 선택한다.
- 냉동 저장소 : 잘 사용되지 않는 비활성 상태의 데이터를 저장하는 곳이다.
Reference
'architecture' 카테고리의 다른 글
| [데이터 중심 애플리케이션 설계] 분산 시스템의 골칫거리 (1) | 2024.06.08 |
|---|---|
| [가상 면접 사례로 배우는 대규모 시스템 설계 기초 2] 호텔 예약 시스템 (0) | 2024.05.21 |
| [가상 면접 사례로 배우는 대규모 시스템 설계 기초 2] 광고 클릭 이벤트 집계 (1) | 2024.05.11 |
| [가상 면접 사례로 배우는 대규모 시스템 설계 기초 2] 분산 메시지 큐 설계 (0) | 2024.04.29 |
| 모놀로식, MSA 장단점 (1) | 2024.03.04 |