
요약, 이벤트 기록, 스냅샷
서버 진단 시, 서버로 부터 수집해야 할 정보는 요약, 이벤트 기록, 스냅샷이다.
- 요약 : 단위 시간 정보의 합계나 평균을 의미하며 sar, vmstat 과 같은 명령어를 통해 확인할 수 있다.
- 이벤트 기록 : packet, system call 과 같은 정보들의 순차적인 기록들을 의미한다.
- 스냅샷 : 순간의 상태를 기록하는 것을 의미하여 현재 문제가 발생하고 있지 않는지, 발생한다면 원인 조사를 하는데 사용한다.
- 요약 정보로 각 리소스의 대략적인 상태를 파악하고 스냅샷으로 원인을 파악한다. 이벤트 기록은 장애 상황에서 사용하기에는 데이터가 방대하여 그 자체에 영향을 줄 수 있으므로 문제 상황 재현 등에 활용한다.
- (⭐️ 중요) 로그, 요약 정보의 일정 수치에 알람 설정을 해두고 스냅샷으로 원인을 파악한다.
USE 방법론
- Utilization : 얼마나 자원을 사용했는지
- Saturation : 얼마나 많은 부하가 몰리는지
- Error : 에러가 발생했는지
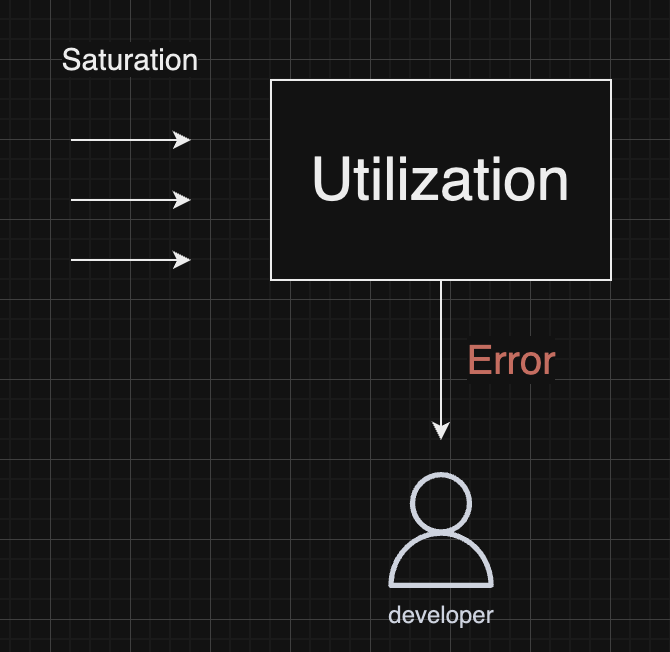
1. USE 의 순서는 Error → Utilization → Saturation
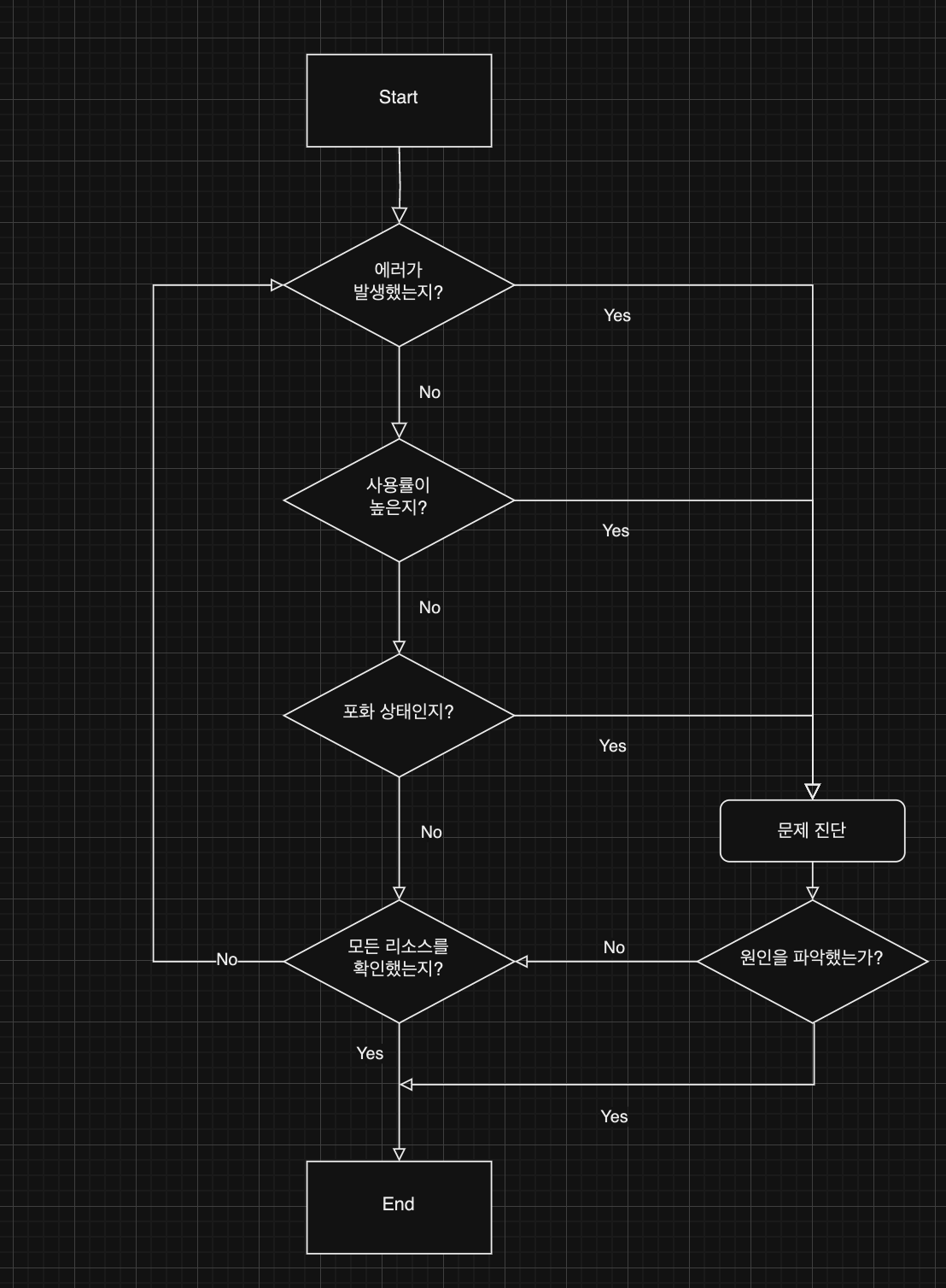
(1) 에러가 발생했는지?
로그 : 시스템 로그와 애플리케이션 로그로 구분된다.
- 시스템 로그
- /var/log/syslog, cron, dmesg(kernel log 출력) 등을 확인한다.
- 애플리케이션 로그
- 관리자가 지정한 에러가 발생한다면, 로그만 확인해도 원인과 해결 방안을 파악하기 용이하다.
- 직전 배포와 연관이 있는지, 특정 사용자, 시간, 조건에 따른 문제인지 확인이 필요하다.
- 에러 로그 전후 맥락을 파악해보고, 어디에서 에러가 발생했는지 코드 확인이 필요하다.
(2) 사용률이 높은지?
서버 장비의 경우, CPU utilization, Available memory, RX/TX 패킷량, Disk 사용률 등을 확인한다.
a. CPU 사용률
- CPU 사용률 : 특정 기간동안 CPU 가 작업을 수행한 전체 시간을 백분율로 측정한 내용
- CPU 는 이론적으로 사용률이 높아도 성능이 급격히 떨어지지 않는다. 커널에서 우선순위에 따라 프로세스나 스레드를 선점해 시분할하기 때문이다.
- 100% 라면 포화 상태를 의미한다. 곧, 대기할 프로세스가 존재하는 것을 의미하며 경험상 최대 70% 이하로 유지한다.
- 서버 종료로 인한 부하분산 요청량이 전가가 되는 것을 고려하면서 scale-in,out 설정을 하도록 하자. (70% + 70% = 140%)
- 서버가 늘어날수록 장애에 따른 각 서버별 부담이 줄어든다.
- CPU 사용률 관리 방법 : 불필요한 작업을 없애거나 개선해보자. (그런데 개선 대상을 어떻게 찾을까??)
- CPU 사용률 지표 : user time, system time, idle, wait I/O, stolen time
- user (user time) vs kernel (system time) 비율을 확인한다.
- 커널 시간은 프로세스 제어, 장치 관리, 파일과 네트워크 입출력 처리 등 시스템 콜을 처리하는데 걸린 시간을 의미한다.
- 유저 시간은 유저 프로세스를 실행하는데 걸린 시간을 의미한다.
- 유저 시간이 높은 경우, CPU 사용률이 높은 프로세스 혹은 스레드를 찾아본다.
- 만약 모든 스레드가 CPU 사용률이 높다면, scale-up(core 수 증가) 를 우선 고려한다.
- 특정 스레드 CPU 사용률이 높다면, 수행 중인 Task 를 분석하고 로직을 개선해야 한다.
- wait I/O 보단 process 의 block 상태를 확인한다.
- stolen time 은 hypervisor 가 차지한 시간이다.
- user (user time) vs kernel (system time) 비율을 확인한다.
- CPU 사용률 지표 : user time, system time, idle, wait I/O, stolen time
b. Memory 사용률
- available memory : 새로운 프로세스나 기존 프로세스에 할당할 수 있는 메모리 양이다.
- 가용 가능 메모리가 부족하면 page fault, swapping 빈도가 높아질 수 있다. 이럴 경우 프로세스 중지 또는 프로세스 재시작 말고는 적절한 방법이 없으므로 평소 여유 메모리 확보가 중요하다.
c. Disk 사용률 (mac command : df -h)
- 부족할 경우 증설, mount, 불필요한 파일 제거한다.
d. Network 사용률
- active/s : 서버에서 다른 외부 장비로 연결한 횟수
- passive/s : 서버에 새로 접근한 클라이언트 수
(3) 포화 상태인지?
단위 시간당 사용률이 낮지만, 부하가 순간 급증하여 포화상태가 되어 성능 문제가 발생할 수 있다.
- 부하 : 처리하려고 해도 실행할 수 없어서 대기하고 있는 프로세스의 수를 의미
a. Load average 가 core 수보다 높은지 (uptime)
- CPU 에서 동작 중인 프로세스가 core 수보다 많은지
- I/O 처리 대기 시간이 급격히 높아지는지
b. I/O 처리 대기시간이 급격히 높아지는지
- 부하가 높다면 스냅샷 확인해보자.
- 프로세스 상태가 R,D 이면서 CPU 사용률이 높은 프로세스를 찾아 원인을 파악한다.
c. memory swap 이 발생하는지
- CPU 가 가용 가능 상태임에도 swapping 이 발생한다면 그것 또한 스레싱일 수 있다.
- 스레싱 : CPU 작업 시간보다 메모리와 스왑 영역 간 페이지 교체에 시간을 많이 소비하는 것
- swap 이 발생한다면 RES 가 큰 프로세스가 없는지 확인한다. (command : top)
- RES : 실제 물리 메모리 영역의 크기
- VIRT : 프로세스가 확보한 가상 메모리 영역의 크기
- 이런 경우 메모리를 늘리거나 더 빠른 메모리를 사용하거나, SSD 를 사용하거나, 메모리 지역성을 향상, 메모리 I/O 양을 줄이는 등의 성능 개선을 해야 한다.
d. network 재전송 비율 (retrans/s) 이 0.5% 보다 높은지
- TCP retransmission : 오류 복구 기능으로, 패킷 손실을 방지하기 위해 발생
- 가령, 애플리케이션 오작동, 라우터의 과부하 트래픽, 일시적인 서비스 정지 등에서 패킷이 손실될 수 있다.
- 이 때 재전송 타이머가 동작하고, linux 경우 최대 15회 이상 재전송하고 그 안에 ACK 를 받으면 정지한다.
- 즉, TCP retrans/ 가 높다는 의미는, application 이 오작동하거나 서버가 트래픽에 대응하지 못하는 등 여러 상황에 의해 패킷 손실이 발생한다는 의미이다. 이에 요청을 처리하지 못하는 포화 상태로 판단하는게 합리적이라 생각한다.
USE 방법론은 한 대의 서버 문제를 파악하는데 유용하지만 여러 서버를 운영하는 분산 환경에서는 RED 방법론을 활용하기도 한다.
RED 방법론
- Rate : 초당 처리한 요청 수
- Error : 처리에 실패해 오류가 발생한 요청 수
- Duration : 요청을 처리하는데 걸린 시간
1. 주로 보는 모니터링 지표들
- Error
- errror count by host
- not success request seconds by url
- Requests
- request seconds (최대 응답시간, 평균 응답시간)
- request count by host
- request count by url
- 사용률 & 포화
- CPU Utilisation by host
- CPU Satuartion (load per cpu) by host
- Memory Utilisation by host
- Memory Saturation (Mager Page Fault) by host
- Memory Swap/Failure
- Net Utilisation by host (Bytes Receive / Transmit)
- Net Satuartion by host (Drop Receive/Transmit)
- Disk IO Uilisation by host
- Disk IO Satuartion
- heap usage by host
- WAS 상태
- JVM live threads by host
- JVM blocked threads by host
- Tomcat busy threads by host
- JVM CPU usage by host
- GC Memory
- DB 상태
- HikariCP Acquire seconds
- HikariCP Creation seconds
- HikariCP DB Connection pool
- Redis 상태
- Cache Misses per Cache Items
서비스 운영 대시보드 만들기 (amazon linux 기준)
1. config.json 설정
- agent : 에이전트의 전체 구성에 대한 필드
- metrics : 수집하여 CloudWatch 에 게시할 사용자 지정 지표를 지정
- metrics_collected : StatsD 또는 collectd를 통해 수집된 사용자 지정 지표를 포함하여 수집할 지표를 지정
- logs : CloudWatch Logs 에 게시되는 로그 파일을 지정
- traces : 수집되어 AWS X-Ray 로 전송되는 추적의 소스를 지정한다.
(참고 : [AWS]수동으로 CloudWatch 에이전트 구성 파일 생성 또는 편집)
{
"agent" : {
"logfile": "/opt/aws/amazon-cloudwatch-agent/logs/amazon-cloudwatch-agent.log",
"metrics_collection_interval": 60,
"region" : "ap-northeast-2",
"run_as_user": "root"
},
"metrics" : {
"append_dimensions" : {
"AutoScalingGroupName":"${aws:AutoScalingGroupName}",
"InstanceId":"${aws:InstanceId}"
},
"aggregation_dimensions" : [["AutoScalingGroupName"], ["InstanceId"]],
"metrics_collected" : {
"cpu" : {
"measurement" : [
"cpu_usage_system",
"cpu_usage_user",
"cpu_usage_iowait",
"cpu_usage_steal"
],
"metrics_collection_interval": 60
},
"mem": {
"measurement": [
"available",
"used",
"total"
],
"metrics_collection_interval": 60
},
"disk" : {
"measurement": [
"used_percent",
"used",
"total"
],
"metrics_collection_interval": 60
},
"netstat" : {
"measurement" : [
"tcp_close_wait",
"tcp_time_wait"
]
}
}
},
"logs" : {
"logs_collected": {
"files": {
"collect_list": [
{
"file_path": "/var/log/**.log",
"log_group_name": "syslog",
"log_stream_name": "{instance_id}",
"timezone": "Local"
}
]
}
}
}
}
sudo /opt/aws/amazon-cloudwatch-agent/bin/amazon-cloudwatch-agent-ctl -a fetch-config -m ec2 -s -c file:/opt/aws/amazon-cloudwatch-agent/bin/config.json
sudo /opt/aws/amazon-cloudwatch-agent/bin/amazon-cloudwatch-agent-ctl -m ec2 -a status
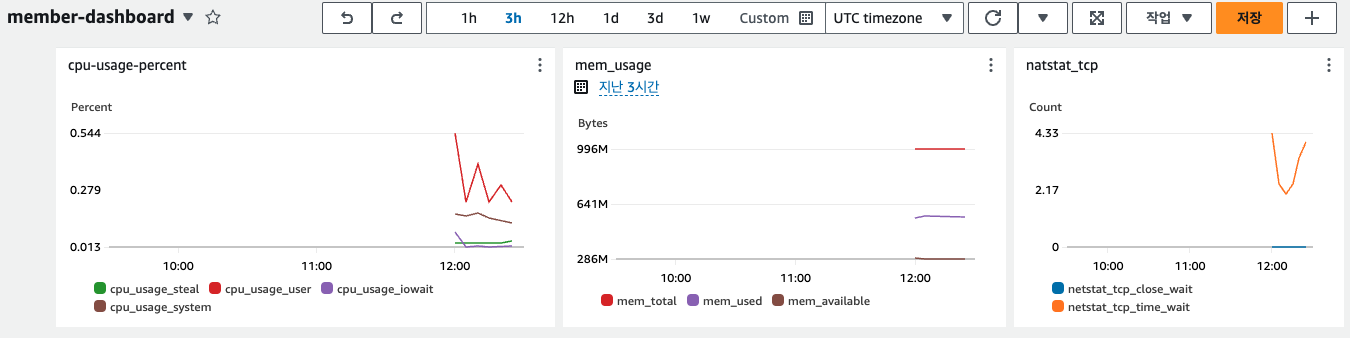
2. CloudWatch dashboard 생성
- CloudWatch > Dashboards > [생성 대시보드] > 위젯 추가
- 위젯 구성 > 지표 > 행 > CWAgent (custom) > 원하는 metric 추가
3. pinpoint 설정
- 이전 글 pinpoint simple summary 참고
Reference
- 인프라 공방 강의
- AWS Cloudwatch
- CloudWatch 에이전트가 수집하는 지표 : https://docs.aws.amazon.com/ko_kr/AmazonCloudWatch/latest/monitoring/metrics-collected-by-CloudWatch-agent.html#linux-metrics-enabled-by-CloudWatch-agent
- 수동으로 CloudWatch 에이전트 구성 파일 생성 또는 편집 : https://docs.aws.amazon.com/ko_kr/AmazonCloudWatch/latest/monitoring/CloudWatch-Agent-Configuration-File-Details.html
- AWS 강의실 - cloudwatch : https://www.youtube.com/watch?v=8t1kmIDtfqc
'인프라 공방 > 컨퍼런스' 카테고리의 다른 글
| [인프라 공방] 컨퍼런스 신청 - 4. 서비스 성능 진단하기 (0) | 2024.03.28 |
|---|---|
| [인프라공방] 컨퍼런스 신청 - 2. 환경 구성 (0) | 2024.03.12 |
| [인프라공방] 컨퍼런스 신청 - 1. github action 을 통한 빌드 설정 (1) | 2024.03.05 |