
1. 분산 시스템에서의 부분 결함
분산 환경에서 결함이 발생하는 원인은 크게 네트워크와 시계 및 타이밍 문제로 나뉜다. 분산 시스템은 기본적으로 부분 장애 가능성을 염두하고 내결함성 매커니즘을 도입해야 한다. 분산 시스템은 부분 장애로 인해 비결정적인 연산이 발생할 수 있기 때문이다. 결정적인 연산은 하드웨어가 올바르게 동작하면 같은 연산은 항상 같은 결과를 낸다는 의미이다.
Internet protocol(IP, 3계층) 은 신뢰성이 낮다. 패킷의 누락, 지연, 중복, 순서 불일치 문제가 발생할 수 있다. TCP(Transmission Control Protocol) 는 손실된 패킷 재전송, 중복 제거, 순서 재조립을 통해 IP 에서의 낮은 신뢰성을 전송 계층에서 보장한다. 하지만, 네트워크 지연에 관한 오류에 대한 신뢰성을 제공하지 않는다. 이와 같이 좀 더 신뢰성 있는 상위 수준 시스템은 완벽하지 않지만 유용하다.
2. 네트워크 결함
[1] 신뢰성 없는 네트워크를 위한 타임아웃과 기약없는 지연
분산 시스템은 연결된 다른 네트워크 장비를 통해 통신할 수 있어 메시지의 도착 시점과 도착 여부를 보장하지 않는다. 전송자 입장에서는 응답 성공 여부와 응답 실패 원인에 대해 알기가 쉽지 않다. 결함 감지를 위한 최소한의 대안책은 타임아웃이다. 타임아웃 값 설정 또한 중요하다. 정상이지만 결함으로 판단하여 연쇄 장애를 유발할 수 있기 때문이다. (e.g. RTT의 증가, 요청량 증가로 인한 응답 지연) 또 다른 방법으로는 파이 증가 장애 감지기를 사용하는 방법도 존재한다.
[2] 네트워크에서 결함 감지
네트워크에서 분산 시스템에서 결함을 감지하기 위한 피드백을 제공한다. 예시는 아래와 같다.
- 요청 노드가 응답 노드의 포트에서 수신 대기 프로세스가 없다면 OS level 에서 RST 또는 FIN 패킷을 응답해 TCP 연결을 닫거나 거부한다. 하지만, 노드가 요청 처리하다 죽으면 실제로 얼마나 처리 되었는지 알 수 없다.
- HBase 에서는 노드 프로세스가 죽었지만 OS level 에서 실행 중이라면 스크립트를 실행하여 상태를 전달한다.
- IP 주소에 도달할 수 없다면 Router 에서 ICMP Destination Unreachable 패킷을 응답할 수 있다.
[3] 동기 네트워크 vs 비동기 네트워크
동기 네트워크는 일정 대역폭을 할당해 데이터를 전송하는 방식이며 대표적인 예시로는 회선(circuit) 을 만들어 사용하는 방식이다. 해당 네트워크는 높은 데이터 전송 신뢰성을 보장하지만, 대역폭을 추정하기 어렵다면 생성을 허용하지 않아 사용할 수 없는 단점이 있다. 비동기 네트워크는 반대로 대역폭을 동적으로 조절하는 방식이다. 대표적인 예로는 인터넷의 패킷 교환 방식이며, 인터넷이 패킷 교환 방식을 선택한 이유는 순간적으로 몰리는 트래픽(bursty traffic) 에 최적하하기 위함이다.
2. 시간적 결함
분산 시스템에서는 통신이 즉각적이지 않으므로 시간은 다루기 까다롭다. 각 네트워크 개별 장비는 수정 발진기(quartz crystal oscillator) 를 가지고 있어 자신의 시간을 갖고 있다. 이 장치는 정확하지 않아 장비별로 시간 차이가 존재하기 때문에 NTP(Network Time Protocol) 를 사용해 서버 그룹에서 보고한 시간에 따라 컴퓨터 시계를 조정할 수 있다.
[1] 단조 시계 vs 일 기준 시계
현대 컴퓨터는 일 기준 시계(time-fo-day clock) 과 단조 시계(monotonic clock) 이 존재한다. 일 기준 시계는 직관적으로 시계에 기대하는 일을 한다. 예시로는 리눅스의 clock_gettime(CLOCK_REALTIME) 과 자바의 System.currentTimeMillis() 는 에포크(epoch) 이래로 흐른 초를 반환한다. (참고로 epoch 는 UTC 1970년 1월 1일 자정을 가리킨다.) 장비의 시간이 빠르거나 느리게 실행되는 것을 시계 드리프트라 부른다.
일 기준 시계는 보통 NTP 로 동기화한다. 동기화의 의미는 장비 간의 타임스탬프를 맞춘다는 의미이다. 하지만 타임스탬프를 맞추는 과정에서 특정 시간을 스킵할 수 있는 위험이 있다. 이런 스킵은 일 기준 시간은 경과 시간을 측정하는데는 적합하지 않게 만들며 해상도가 낮은 단점이 있다.
단조 시계는 타임아웃과 서비스 응답 시간과 같이 지속 시간을 재는 데 적합하다. 예시로는 리눅스의 clock_gettime(CLOCK_MONOTONIC) 과 자바의 System.nanoTime() 이 있다. 단조 시계는 두 값 사이의 차이로 경과 시간을 측정한다. 이 방식은 다른 컴퓨터에서 나온 단조 시계 값을 비교하는 것은 의미가 없다. NTP 를 통해 로컬 시계를 조정할 경우, 시계 속도를 조절할 수 있지만(~0.05%), 앞으로 또는 뒤로 뛰게 할 수 는 없어 해상도가 상당히 높다.
[2] 이벤트 순서화용 타임스탬프
일 기준 시계에 의해 다중 리더 복제 환경에서 갱신 손실(lost update) 문제가 발생할 수 있다. 비록 충돌 해소를 위해 LWW(last write wins) 전략을 선택할 수 있지만 본질적인 문제를 해결할 수 없다. NTP 를 동기화를 통해 해결하는 것도 한계가 있다. RTT 와 같은 네트워크 지연을 극복하기는 쉽지 않다.
기존에 사용하던 일 기준 시계와 단조 시계를 사용하는 방식은 물리적 시계(physical clock) 이라 부른다. 하지만 이 방식은 한계가 존재한다. 반대로 논리적 시계(logical clock) 가 있다. 논리적 시계는 카운트를 기반으로 하여 이벤트 순서를 안정화할 수 있다. 즉, 이벤트의 상대적인 순서만 측정하는 방식이다.
- mysql commit_order
[2] 신뢰 구간, 전역 스냅숏용 동기화된 시계
일 기준 시계는 마이크로초, NTP 서버 사용해도 수십 밀리초 정도의 해상도로 읽을 수 있다. 불확실성의 경계는 시간 출처를 기반으로 계산할 수 있지만 대부분의 시스템은 불확실성을 노출하지 않는다.
DB의 스냅숏 격리에서 또한 시계 정확도의 불확실성을 고려해야 한다. 일 기준 시계, 단조 시계를 이용하는 방식에는 한계가 있으므로 스패너의 트루 API 를 사용할 경우, 신뢰 구간이 겹치치 않도록 신뢰 구간 길이 만큼 길이를 기다리는 방식을 선택하기도 한다. (Ae < Al < Be < Bl) 아직까지는 DB 에서 구현한 사례는 없다고 한다.
3. 부분 결함으로 인한 문제
[1] 프로세스 중단
리더가 존재하는 분산 시스템에서 스레드 중단으로 인해 올바른 리더 임차권이 보장되지 않는 환경이 발생할 수 있다. 즉, 분산 시스템에서 race condition 이 발생할 수 있다. 스레드가 중단될 수 있는 환경으로는 GC, context switch, thrashing 이 있다. 단일 장비에서는 뮤텍스, 세마포어, 원자적 카운터, 잠금없는 자료구조, 블로킹 큐 등을 사용해 해결할 수 있지만 분산 시스템은 공유 메모리가 없고 네트워크의 신뢰성 한계로 인해 한계가 있어 이와 같은 부분은 주의해야 한다.
스레드 대기 시간이 길어지면 심각한 손상이 발생할 수 있으므로 데드라인을 명시해야 한다. 데드라인을 설정하는 이유는 예측 가능하게 응답해야 하기 위함이다. 이와 같은 시스템을 엄격한 실시간 시스템(hard real-time)이라 부른다. 실시간 보장을 제공하기 위해서는 프로세스 명시된 간격의 CPU 시간을 할당받을 수 있게 보장되도록 스케줄링해 주는 실시간 운영체제(RTOS) 가 필요하다.
- 실시간은 고성능과 동일하지 않다. 그러므로 제때에 응답하는 것을 우선시해야 하므로 처리량이 더 낮을 수도 있다. 대부분의 서버측 데이터 처리 시스템에게 실시간 보장은 전혀 경제적이지도, 적절하지 않다.
- GC 중단을 경고한다면 애플리케이션은 처리하지 않는 동안 GC 를 실행하기를 기다릴 수 있다.
[2] 다수결
분산 시스템에서는 한 노드의 판단만을 믿지 않고 노드들 사이의 최소 투표 수에 의존하는 정족수(quorum)를 사용해 해당 기능의 노드들의 기능 헬스체크를 할 수 있다는 것을 전달할 수 있다.
[3] 펜싱 토큰
펜싱 토큰(fencing token)은 잘못 믿고 있는 노드가 나머지 시스템을 방해할 수 없도록 보장하기 위한 방법 중 하나이다. 잠금 서비스로 주키퍼를 사용하면 트랜잭션 ID(zxid) 나 노드 버전(cversion) 을 펜싱 토큰으로 사용할 수 있다. 참고로 단조 증가가 보장되는 필요한 속성을 지닌다.
[4] 비잔틴 결함
분산 시스템은 비잔틴 내결함성을 지녀야 한다. 일부 노드가 오작동하고 프로토콜을 주누하지 않거나 악의적인 공격자가 네트워크를 방해하더라도 계속 올바르게 동작해야 한다. 웹에서는 클라이언트의 행동을 임의적이고 악의적이라 예상해야 한다. 그러므로 입력 확인, 살균, 출력 이스케이핑을 통해 XSS 나 SQL injection 과 같은 보안 취약점에 대비해야 한다.
- 비잔티움 장군 문제 - 여러 부대가 지리적으로 떨어진 곳에서 공격할 때, 배신자의 존재에도 충직한 장군들이 동일한 공격을 하기 위해 필요한 충직한 장군의 수와 규칙에 관한 문제를 다루는 것이다.
스터디 summary
1. discussion
page295. 트랜잭션 타임스탬프가 인과성을 반영하는 것을 보장하기 위해 스패너는 읽기 쓰기 트랜잭션 커밋하기 전에 의도적으로 신뢰 구간의 길이만큼 기다린다. 그렇게 하면 그 데이터를 읽을지도 모르는 트랜잭션은 충분히 나중에 실행되는 게 보장되므로 신뢰 구간이 겹치지 않는다.
- Spanner?? Google이 만든 NewSQL로, 전 세계의 데이터센터에 데이터를 분산 저장한다. Spanner는 RDBMS 만큼의 정합성을 제공하면서도 하나의 데이터 센터 규모를 넘어서는 많은 데이터를 저장할 수 있다.
- 락을 획득하고 완료될 때까지 신뢰구간 대기했다가 트랜잭션이 완료되고 다른 트랜잭션에 공지하는 방식으로 이해
- https://d2.naver.com/helloworld/216593
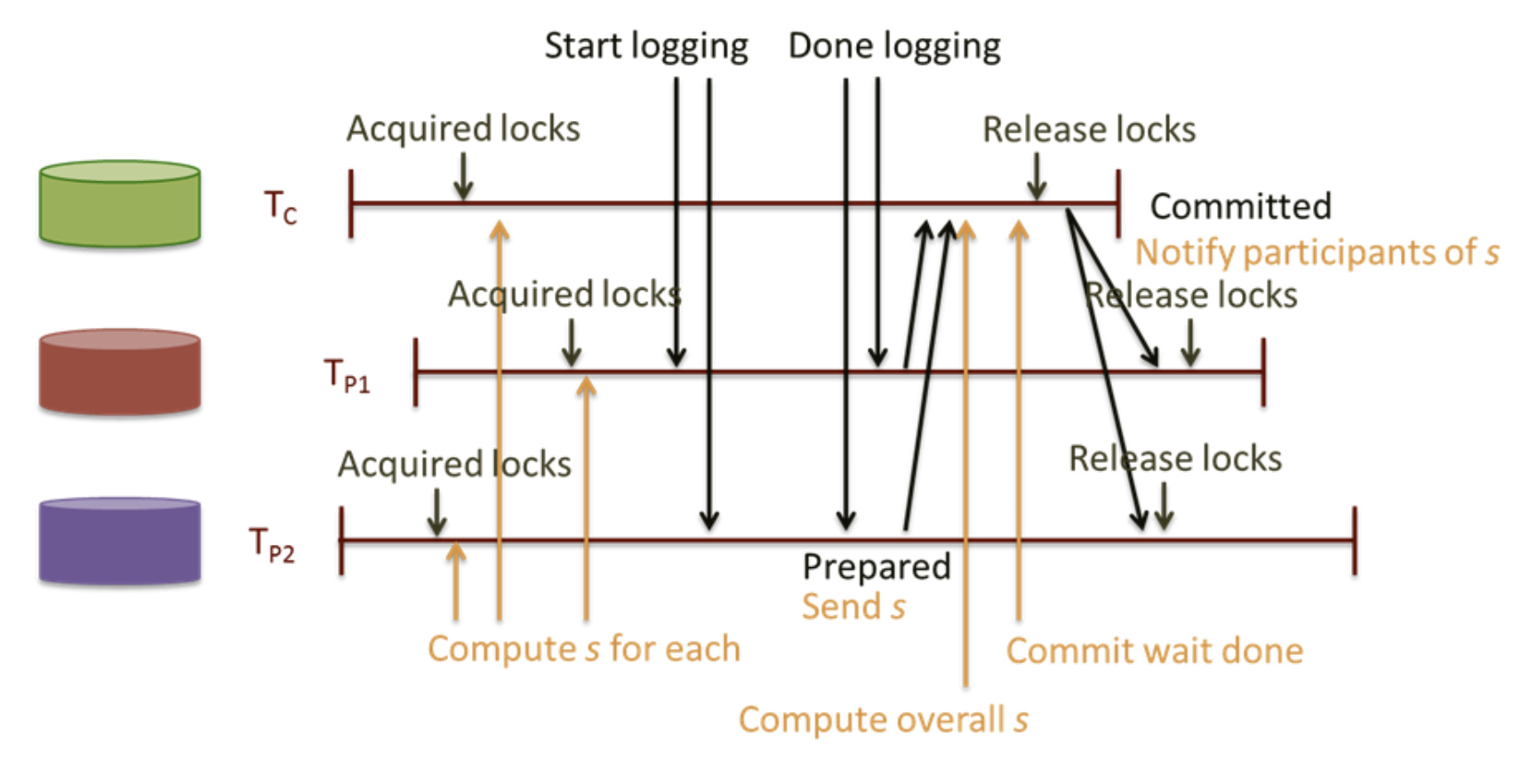
공유 내용
- NTP 관련 이슈 경험 공유 기록 - google OTP 생성 노드와 인증 노드의 시간 차이로 인한 미동작 이슈
- MSA 의 장점은 개발, 배포 독립성을 보장 가능한 이점과 부분 장애를 전체 장애로 에러 전파를 하지 않는 점이다.
- NoSQL 은 완전한 다중 객체 트랜잭션을 지원하지 않는 경우가 많아 아직 mongoDB 를 사용해본 경험이 없어 확실하지는 않다.
- reference link : https://github.com/wikibook/data-intensive-applications
'architecture' 카테고리의 다른 글
| [데이터 중심 애플리케이션 설계] 스트림 프로세싱 (0) | 2024.07.01 |
|---|---|
| [데이터 중심 애플리케이션 설계] 일관성과 합의 (0) | 2024.06.19 |
| [가상 면접 사례로 배우는 대규모 시스템 설계 기초 2] 호텔 예약 시스템 (0) | 2024.05.21 |
| [가상 면접 사례로 배우는 대규모 시스템 설계 기초 2] 광고 클릭 이벤트 집계 (1) | 2024.05.11 |
| [가상 면접 사례로 배우는 대규모 시스템 설계 기초 2] 지표 모니터링 및 경보 시스템 (0) | 2024.05.04 |